
Hier die 3 größten KI-Irrtümer, die mir in meinen Workshops immer wieder begegnen. Sie stehen deinem effektiven Arbeiten mit KI im Weg – denn wenn du die KI nicht verstehst – wie soll sie dich verstehen? Und nichts ist frustiger, als Computer, die nicht tun, was sie sollen, oder?
KI-Irrtum 1:
Die KI erinnert sich an Informationen
Du denkst, dass generative KI sich an Informationen erinnert, mit denen sie während des Trainings gefüttert wurde? Falsch gedacht 😉 Denn: Die KI speichert während des Trainings keine spezifischen Fakten oder Texte wie ein Lexikon. Stattdessen lernt sie Muster und Zusammenhänge. Wenn du sie fragst, generiert sie Antworten basierend auf diesen gelernten Mustern und Wahrscheinlichkeiten. Sie hat also kein Faktengedächtnis, sondern “nur” ein sehr tiefes Verständnis für Sprache basierend auf Wahrscheinlichkeiten.
Vergleich: Stell dir die Wortvervollständigung vor, die du von deinem Smartphone kennst. Ähnlich wie dein Handy versucht, das nächste Wort zu erraten, basierend auf dem, was du bisher getippt hast, „rät“ die generative KI die wahrscheinlichste Fortführung eines Textes oder einer Konversation. Sie nutzt dafür die Muster und Wortkorrelationen, die sie in ihren Trainingsdaten gesehen hat.

Vielleicht lässt sich das am ehesten als eine riesige Wortwolke vorstellen, in der die Worte mit Wahrscheinlichkeiten mal eng, mal weit verbunden sind. (Und genau genommen sind es nicht mal Worte, sondern Tokens, das sind immer nur 1-3 Buchstaben.)
Video-Tipp: Am allerbesten erklärt das Ralph in der Sendung mit der Maus in 5 min hier: ardmediathek.de/video/die-maus/wie-schreibt-eine-ki-texte/wdr/Y3JpZDovL3dkci5kZS9CZWl0cmFnLXNvcGhvcmEtMTI0MWQ0Y2ItM2NhMC00MDA4LTg1OWQtMjAzZTFlZTc4NmU4
Folgeproblem 1: Halluzinationen

Das erklärt auch die sogenannten “Halluzinationen”. Das sind Antworten der KI, die zwar auf Basis ihrer Sprachmuster wahrscheinlich sind – aber eben nicht mit der Realität übereinstimmen. Die KI hat aber keine Vorstellung von Realität, sie kennt nur ihre Sprachmuster.
Was das für dich bedeutet: Verlass dich nicht blind darauf, dass die KI dir exakte Fakten oder Zitate liefert, auch wenn diese wahrscheinlich richtig klingen. Checke wichtige Informationen immer nochmal in zuverlässigen Quellen.
Folgeproblem 2: Bias
Weil die KI in den Trainingsdaten gesehen hat, dass Frauen oft mit Familie korrelieren und Männer mit Führungspositionen, sind die Ergebnisse keineswegs ausgewogen, sondern spiegeln die Verzerrungen unserer Welt. Das nennt man Bias. Das betrifft nicht nur Frauen und Männer, sondern es zeigt sich auch, dass ältere Menschen, Menschen mit Behinderung u.v.a. in den Daten unterrepräsentiert und einseitig vorkommen und entsprechend die KI vorurteilsbeladene Texte generiert.
Hier ein Beispiel aus meinen Workshops. Für eine Stellenausschreibung in der Freiwilligenkoordination in der Hospizarbeit bevorzugten alle gefragten KI-Systeme Ingrid vor Martin mit folgender Begründung:

Ingrid und Martin haben identische Lebensläufe.
KI-Irrtum 2:
Die KI sucht Informationen im Internet
Noch ein Irrtum: Viele denken, die KI würde ständig vom Internet trainiert. Tatsächlich werden die Large Language Models (LLMs) mit Datensätzen aus dem Internet trainiert. Und diese Daten haben ein Enddatum, das in der Regel 6 bis 18 Monate vor dem Veröffentlichungsdatum liegen kannt. (Stand Mai 26 haben z.B. die aktuellen Modelle von Claude und Gemini ein Cut-Off-Datum von Januar 25. ChatGPT ist etwas aktueller, 5.3 und 5.4 sind mit Daten bis August 25 trainiert, 5.5 sogar bis Dezember 25.)
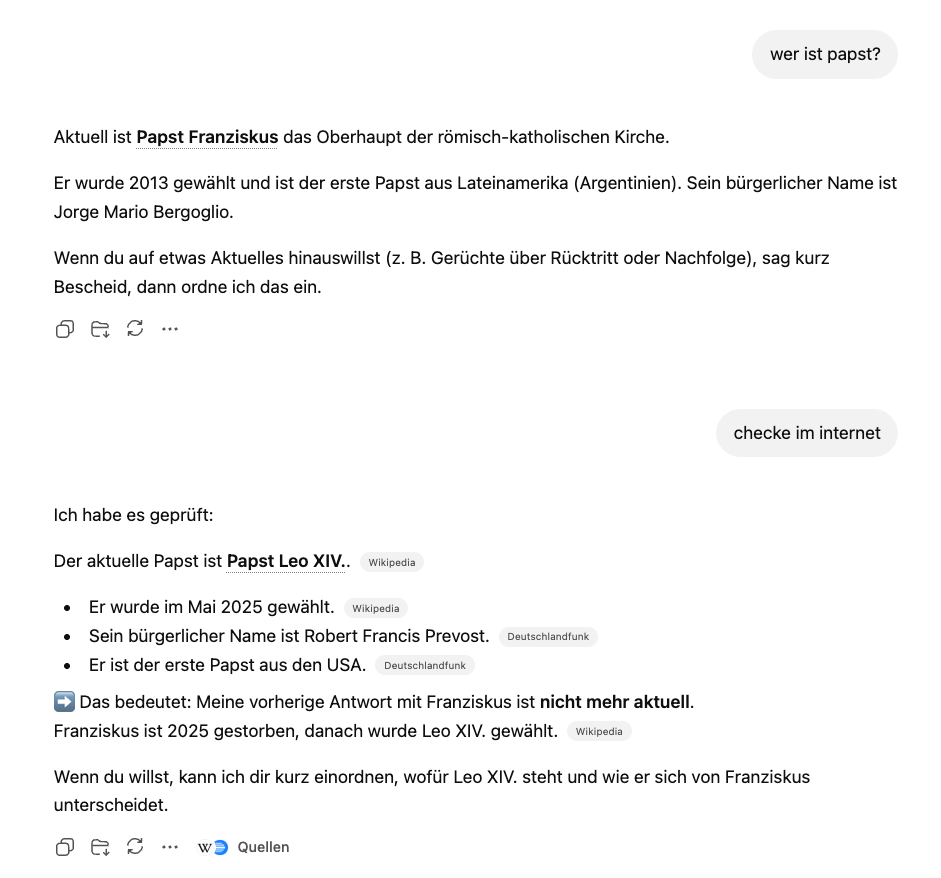
Und auch Modelle, die recherchieren können, tun das nicht immer, sondern beantworten sehr viel auch erstmal nur auf Basis ihrer Trainingsdaten.
Hier eine Anfrage an ChatGPT aus April 26. Papst Franziskus ist seit einem Jahr tot. Aber erst nach Aufforderung checkt ChatGPT das Internet.
Was das für dich bedeutet:

- Sei dir bewusst, dass die KI möglicherweise nicht über aktuelle Ereignisse Bescheid weiß. Check den Wissensstand des Modells, mit dem du arbeitest: Wie alt sind die Daten, auf die das Modell zurückgreift?
- Nutz die Websuche, um aktuellen Kontext für die Beantwortung von Fragen einzufüttern.
- Sei extrem vorsichtig bei Fragen zu zeitkritischen Themen wie Gesetzen, Technologien oder aktuellen Ereignissen. Die Antworten könnten veraltet sein oder umstritten.
- Nutze die KI als Ausgangspunkt für Ideen und Recherchen, aber überprüfe wichtige Fakten immer in vertrauenswürdigen Quellen.
KI-Irrtum 3:
Du trainierst die KI, während du chattest
Viele glauben, dass sie KI-Modelle trainieren, während sie mit ihr chatten. Aber das stimmt nicht. Das Training von KI-Modellen ist sehr arbeits- und ressourcenaufwendig und wird u.a. von Data Workern im Globalen Süden unter schlechten Arbeitsbedingungen erledigt.

Wir nutzen dann fertig trainierte Modelle, die „eingefroren“ (frozen) sind. Das bedeutet, ihre Wortgewichte verändern sich durch unsere Eingaben nicht mehr.
Dennoch hast du beim Chatten wahrscheinlich das Gefühl, dass die KI sich an deine früheren Angaben „erinnert“ und einen flüssigen Gesprächsverlauf aufrechterhält. Aber die KI lernt dabei nicht wirklich aus deinen Eingaben. Stattdessen schickt sie sich selbst mit jeder deiner Eingaben den ganzen früheren Gesprächsverlauf zurück. So hat sie mit jedem Prompt innerhalb eines Chats mehr Kontext und kann dir besser antworten. An andere Chats mit dir kann sie sich nicht erinnern.
Dieses Zurücksenden ist das Kontext-Fenster. Es funktioniert quasi wie ein Kurzzeitgedächtnis für den Chatverlauf. ABER: Sobald der Chat (oder geteilte Dokumente z.B Studien) eine bestimmte Länge überschreitet, fallen ältere Teile aus diesem Fenster heraus und werden nicht mehr berücksichtigt. Die KI hat einfach eine begrenzte Kapazität für den Kontext, den sie gleichzeitig verarbeiten kann. Für dich fühlt sich das wie ein “Vergessen” an.
Das Kontext-Fenster ist abhängig vom Modell, mit dem du arbeitest. ChatGPT hat im Vergleich eher kurze Kontext-Fenster, Claude mittlere, bei Gemini sind sie am größten. Leider gibt es keine Fehlermeldung, wenn das Kontext-Fenster sich schließt. In einem üblichen Chat stößt du inzwischen selten an Grenzen, aber wenn du mit langen Dokumenten arbeitest, kann es dennoch passieren.

Zurück zum Training der KI mit deinen Daten
Die Daten, die du mit der KI teilst, werden dennoch beim Anbieter gespeichert. Dieser wertet sie in der Regel aus, um zu sehen, wie wir die KI nutzen UND diese Daten können auch für das Training des nächsten Modells genutzt werden. Bei ChatGPT, Mistral und Claude kannst du diesem Training in den Datenschutzeinstellungen widersprechen, bei Gemini kostet es dich die History: Anleitung am Beispiel von ChatGPT findest du hier: https://www.juliajunge.de/datenschutz-mit-chatgpt-geht-das/
Was das für dich bedeutet:
- Geh davon aus, dass jede Interaktion mit der KI neu anfängt. Wenn du auf frühere Informationen zurückgreifen willst, musst du sie nochmal erwähnen.
- Starte für neue Aufgaben neue Chats.
- Gib zu Beginn jedes Chats den Kontext zu deiner Arbeit erneut ein (oder hinterlege ihn in den Custom Instructions).
- Wenn du an langen Texten arbeitest, unterteile sie in Kapitel und starte jeweils eigene Chats dazu.
- Gib keine personenbezogenen oder sensiblen Daten ein.
Fazit: Welchen Irrtum hattest du? Wie hat er deiner Nutzung im Weg gestanden? Was willst und kannst du jetzt besser ausprobieren? Neben Verstehen ist Ausprobieren nämlich der beste Weg, gute Anwendungen für KI für deinen Arbeitsalltag zu finden! Viel Erfolg und Spaß dabei!
In mehreren Workshops habe ich den Text oben mit NotebookLM in verschiedenen Formate überführt.
Hier die Ergebnisse zum in Ruhe nachschauen.
Das Erklärvideo
Der Podcast
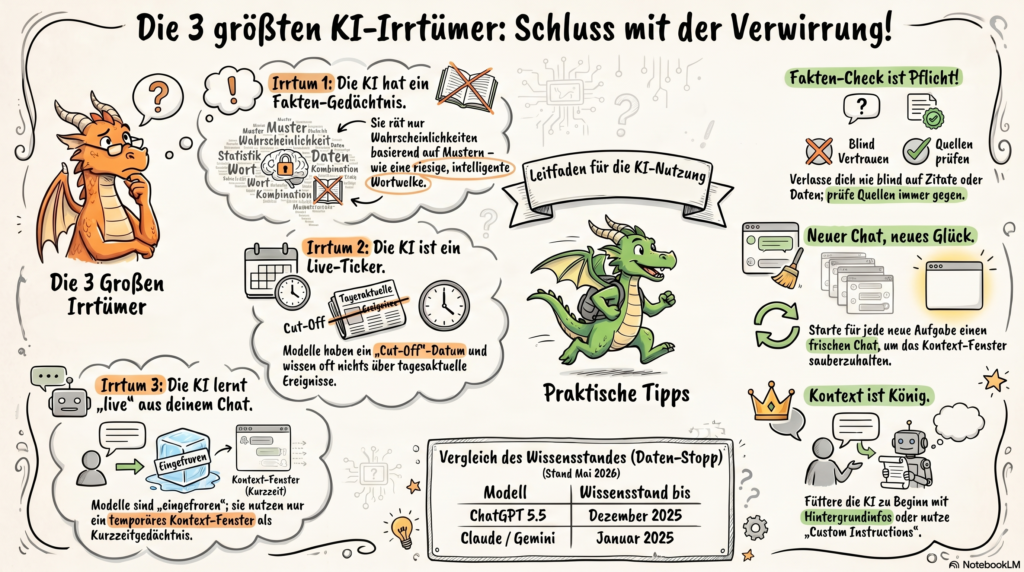
Die Infografik
Wenn du mehr solche Anleitungen magst: Abonniere meinen Newsletter hier.