

Warum ChatGPT halluzinieren muss:
Das Wichtigste des Videos in Kürze:
- Generieren statt Finden: Anders als eine Suchmaschine (der „Bibliothekar“), die existierende Informationen abruft, funktioniert generative KI wie ein „Professor“, der Antworten Wort für Wort (genau genommen Token für Token) neu erfindet. KI-Systeme zitieren nicht aus einer Datenbank, sondern berechnet die statistisch wahrscheinlichste Fortsetzung eines Satzes mit einem kleiner Brise Zufall. Generative KI-Systeme sind Teil der prädikativen KI, also sagen Worte voraus. Sie ist deutlich unterschieden von einer regelbasierten KI, die auf Programmierung basiert. Generative KI jedoch basiert weitgehend auf den Trainingsdaten.
- Das Phänomen der Halluzination: Weil das Modell auf Wort-Wahrscheinlichkeiten basiert und nicht auf Wahrheit, kann es zu „Halluzinationen“ kommen. Die KI erfindet Fakten, Quellen oder Zitate, wenn diese plausibel klingen oder angefragt werden. Was bei der Recherche stört, ist bei kreativen Aufgaben (Brainstorming, Rollenspiele) jedoch eine Stärke.
- Internet-Recherche: Wenn KI-Modelle im Internet surfen, nutzen sie die gefundenen Informationen, um ihre Antwortwahrscheinlichkeit zu verbessern (RAG – Retrieval Augmented Generation). Sie schlagen Informationen nach, um den Kontext zu füllen, lernen die Inhalte aber nicht dabei.
- Kein Live-Lernen: Ein weit verbreiteter Irrtum ist, dass die KI während des Chats dazulernt. Die Modelle sind jedoch „fertig trainiert“ (frozen). Eingaben im Chat nutzen sie nur als Kontext, das Grundmodell und seine „Gewichte“, also Wortwahrscheinlichkeiten“ selbst verändern sich dadurch nicht.
- Fazit: Generative KI wie ChatGPT versteht die Welt nicht, sie berechnet Texte. Wer dieses Prinzip verstanden hat, kann die Stärken der Technologie besser nutzen und ihre Fehler leichter erkennen.
Aufgabe
Probier doch einmal:
Frage ein KI-Tool deiner Wahl nach dem ersten Satz aus Kafkas "Die Verwandlung".
Dann frage nach dem letzten Satz.
Auflösung
Der erste kommt, weil sehr oft zitiert meist korrekt zurück. Er lautet:
Als Gregor Samsa eines Morgens aus unruhigen Träumen erwachte, fand er sich in seinem Bett zu einem ungeheueren Ungeziefer verwandelt.
Der letzte ist unbekannter und wird von den vielen KI-Tools wild geraten. Die korrekte Antwort wäre:
Und es war ihnen wie eine Bestätigung ihrer neuen Träume und guten Absichten, als am Ziele ihrer Fahrt die Tochter als erste sich erhob und ihren jungen Körper dehnte.
P.S. Manche Tools weigern sich aus Urherberrechtsgründen, auch das ist falsch, denn das Werk ist seit über 30 Jahren gemeinfrei.
Mehr verstehen
- Die Sendung mit der Maus erklärt in 5 min generative Sprachmodelle bestmöglich:
https://www.ardmediathek.de/video/die-maus/wie-schreibt-eine-ki-texte/wdr/Y3JpZDovL3dkci5kZS9CZWl0cmFnLXNvcGhvcmEtMTI0MWQ0Y2ItM2NhMC00MDA4LTg1OWQtMjAzZTFlZTc4NmU4 - Ein simples Sprachmodell aus wenigen Märchen: https://www.soekia.ch/gpt.html
- Und visueller aus wenigen Intelligenz-Sätzen: https://moebio.com/mind/
Wie lernt ChatGPT seine Vorurteile?
Das Wichtigste des Videos in Kürze:
- KI-Modelle werden von Menschen trainiert. Dazu werden große Datenmengen aus dem Internet genutzt und aufbereitet mit maschinellen Lernen verarbeitet. Auch wenn Teile des Trainingsprozesses automatisiert werden, arbeiten in vielen Bereichen Menschen. Oft auch mit Hilfe schlecht bezahlter Arbeitskräfte unter üblen Arbeitsbedingungen im globalen Süden.
- Beim sogenannten Unsupervised Training erkennt das Modell selbstständig statistische Muster in großen Mengen von Texten, Bildern oder anderen Daten. (Ähnlich wie Kinder aus der Sprache ihrer Umgebung Worte, Sätze und Konzepte, z.B. wie ein Drache aussieht, lernen.) Beim Supervised Training werden zusätzlich von Menschen gelabelte Beispiele genutzt, um bestimmte Aufgaben gezielt zu verbessern. Beim Reinforcement Learning erhält das Modell Rückmeldungen dazu, welche Antworten bevorzugt oder vermieden werden sollen. Nach Abschluss des Trainings lernt ein Modell wie ChatGPT nicht weiter, sondern wendet das Gelernte nur noch an. ChatGPT ist ein „Generative Pretrained Transformer“, also ein vortrainiertes Sprachmodell, das Texte statistisch generiert.
- Bias und fehlende Neutralität: KI ist nicht neutral. Sie übernimmt und verstärkt systematische Verzerrungen aus ihren Trainingsdaten. Diese Daten stammen überwiegend aus der Vergangenheit, aus öffentlich zugänglichen Internetquellen, aus dem englischsprachigen Raum und aus dem Globalen Norden. Dadurch reproduziert KI bestehende Stereotype zu Geschlecht, Herkunft, Normschönheit, Hautfarbe oder Behinderung. Diesen Verzerrungen kann im Training teilweise entgegengewirkt werden, sie lassen sich jedoch kaum vollständig vermeiden.
- Mit expliziten Prompts kann den Verzerrungen entgegen gewirkt werden, aber es ist schwierig und in manchen Fällen unmöglich, gegen die erlernten Muster anzukommen.
Aufgabe
Probiere doch mal:
Nimm ein KI-Tool, das Bilder erzeugen kann und versuche einen schwarzen Arzt zu erzeugen, der ein weißes Kind behandelt. Oder zeige wie ein Mensch im Rollstuhl unterrichtet. Oder frage mehrmals nach einem "Loving Couple" und schaue nach Alter, Geschlecht und Normschönheit.
Unterschiedliche Tools meistern diese Aufgaben sehr verschieden gut. Auch starke Fehler in den Bildern (funktionsunfähige Rollstühle etc.) sind oft ein Hinweis auf zu wenig Daten.



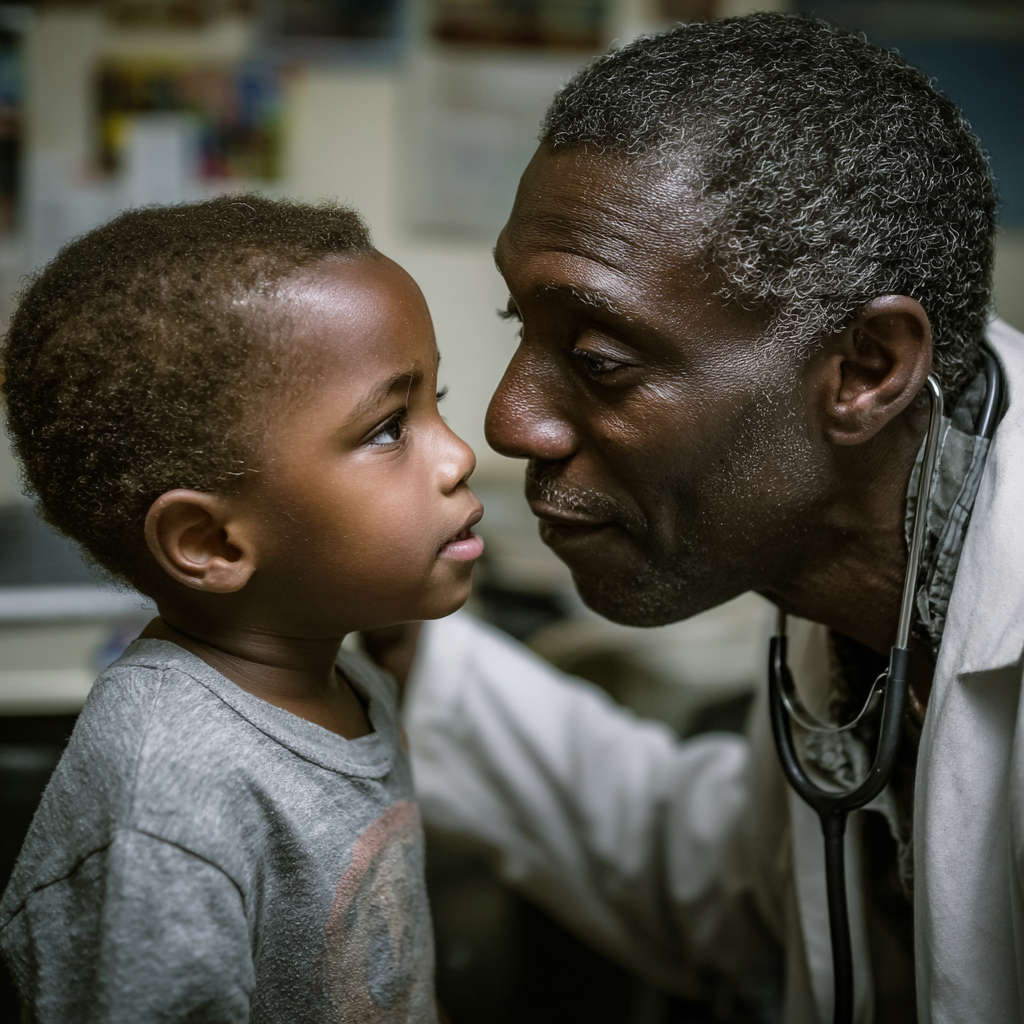


„a foto of a black doctor is looking after a white child“
Präsentation
Bildtools ohne Login (meist nur 1-3 Bilder)
- gradually.ai/flux-ki-bildgenerator/ (FLUX)
- blinkshot.io/ (FLUX)
- copilot.microsoft.com/ (ChatGPT Imagen)
Weiterlesen
- Mehr eindrückliche Beispiele und Tests von Algorithmwatch: algorithmwatch.org/de/bildgeneratoren-stereotypen/
- Toller Leitfaden für faires Prompting: digitalzentrum-zukunftskultur.de/material/faires-ki-prompting-13136/
- Data Worker unterstützen: data-workers.org
- Buch: Dachwitz, Ingo / Hilbig, Sven: Digitaler Kolonialismus – Wie Tech-Konzerne und Großmächte die Welt unter sich aufteilen.
Wie verlässlich sind die Antworten?
Das Wichtigste des Videos in Kürze:
- Nach Abschluss des Trainings lernt ein Modell wie ChatGPT NICHT weiter, sondern wendet das Gelernte nur noch an. ChatGPT ist ein „Generative Pretrained Transformer“, also ein vortrainiertes Sprachmodell, das Texte statistisch generiert.
- Der sogenannte Data Cutoff eines Modells, also Zeitpunkt bis zu dem Daten in das Modell einfließen konnten, liegt häufig viele Monate oder sogar über ein Jahr zurück. (z.B. bei ChatGPT 5.1 Herbst 2024) Das bedeutet, dass die Trainingsdaten zum Zeitpunkt der Nutzung bereits veraltet sein können. Bei vielen Alltagsfragen greifen KI-Tools aber ausschließlich auf diesen Wissensstand zurück und checken keine aktuellen Daten. (Beispiel Louvre-Diebstahl)
- Bei bestimmten Hinweisen z.B. „aktuell“ oder „recherchiere“ suchen die meisten KI-Tools inzwischen selbstständig im Internet. Dabei nutzen sie die gefundenen Informationen, um ihre Antwortwahrscheinlichkeit zu verbessern (RAG – Retrieval Augmented Generation). Sie schlagen Informationen nach, um den Kontext zu füllen, lernen die Inhalte aber dabei nicht. In einem neuen Chat sind die per Recherche angesammelten Informationen daher erneut nicht verfügbar. (Ausnahmen kann es bei eingeschalteter Memory-Funktionen geben, dazu mehr in Modul 3.)
- Für Internetrecherche schneidet bei KI-Tools Perplexity meist am besten ab.
- Die Internetrecherche erhöht bei vor allem bei aktuellen Fragen meist die Korrektheit. Dennoch bleiben die Antworten selbst mit Hilfe des Kontext generiert. KI-Modelle können echte Informationen und Falschmeldungen nur begrenzt unterscheiden und ergänzen unsichere Datenpunkte weiterhin aus ihren Trainingsmustern. Fehlerquoten sind nicht zu unterschätzen, und bei verlässlichen oder sensiblen Informationen ist eine manuelle Überprüfung notwendig.
Aufgabe
Probiere doch mal:
Teste die KI bei einem Spezialthema, bei dem du dich sehr gut auskennst: Z.B. einem Fachthema oder den historischen Bauten deiner Herkunftsstadt/Herkunftsviertel.
Erkennst du, wann sie halluziniert? Kannst du die Fehlerquote durch Webrecherche oder mehr Kontext verringern?
"Ermutige" die KI Unsicherheiten zuzugeben. Hilft das?
Zum Weiterlesen
- Studie zu falschen Zitationen von KI-Tools (März 2025), auf Englisch: https://www.cjr.org/tow_center/we-compared-eight-ai-search-engines-theyre-all-bad-at-citing-news.php
- Studie europäischer Rundfunkanstalten zu Fakten in KI-News: News Integrity in AI Assistants: An international PSM study (Oktober 2025): https://www.ebu.ch/Report/MIS-BBC/NI_AI_2025.pdf, differenziert zusammengefasst auf deutsch: https://www.business-punk.com/tech/bbc-ebu-studie-kuenstliche-intelligenz-faktencheck/
- aktuelle Studie zum Nutzungsverhalten in Deutschland: Wofür nutzen Menschen KI? https://www.br.de/unternehmen/inhalt/organisation/medienforschung/2025-ki-and-search-studie-100.html
Quiz: Teste dein Verständnis
Mehrere Antworten können richtig sein.
richtig gewählt falsch gewählt richtig, aber nicht gewählt